 Photo by Yancy Min on Unsplash
Photo by Yancy Min on UnsplashSomething I’ve noticed more lately, is this trend of having several npm micro-packages all contained in one repository. Many popular open-source projects adopt this pattern, React, Parcel, Babel, and many more. I would argue that in the majority of cases, this pattern is more detrimental to a project than a benefit, introducing unnecessary complexity at the cost of usability for both the author and the developer.
Why Monorepos?
The idea of monorepos is to ease dependency management. If your project contains a lot of packages that need to depend on certain versions of each other, rather than having them in separate repositories, having them in one place can make it easier to manage them all. Also with one history, these packages will always have commits that are in sync or “atomic”. To make things even easier, there can be custom scripts that can manage the releases of all packages automatically so that there’s never a moment when one package is released without its corresponding package.
A JavaScript monorepo project would typically have this type of structure:
myproject.git/
packages/
package-1/
package.json
package-2/
package.json
package-3/
package.json
...
scripts/
common-publishing-script.jsThis is just a small example, but to demonstrate how large some of these monorepos can get:
- React: 32 packages
- Parcel: 81 packages
- Babel: 138 packages
This is absurd in my opinion, and below I’ll explain some of the reasons I’m against the concept of monorepos, and why I believe this is an anti-pattern.
Masking the monolith
There’s several benefits to splitting code into multiple packages, whether it be a library, micro-services or micro-frontends. It results in significantly faster builds, can do independent deployments, and parallelise development across multiple teams, all integrating through an agreed API that everyone can rely on. However, if all of these are hosted in the same repository, you lose a lot of those benefits.
While it might seem initially that monorepos don’t have the same problems of a monolith and that you can maintain packages individually, when you inspect these repositories further, the monolith becomes very apparent. There’s typically a complex tree of dependencies, where packages all tend to rely on each other in order to function.
If you introduce changes to one of the packages, that will likely have a knock-on effect on the packages that consume that package, which in themselves would have to be updated and released. After all, that’s why it’s in one repository to begin with right? Very often in these monorepos, packages are so incredibly specific in functionality, the question then becomes why even have a separate package at all if it’s tightly coupled? Can you use these packages independently or are they tied to specific versions of other packages in the monorepo? It’ll probably be easier to remove the mask and just work as a monolith.
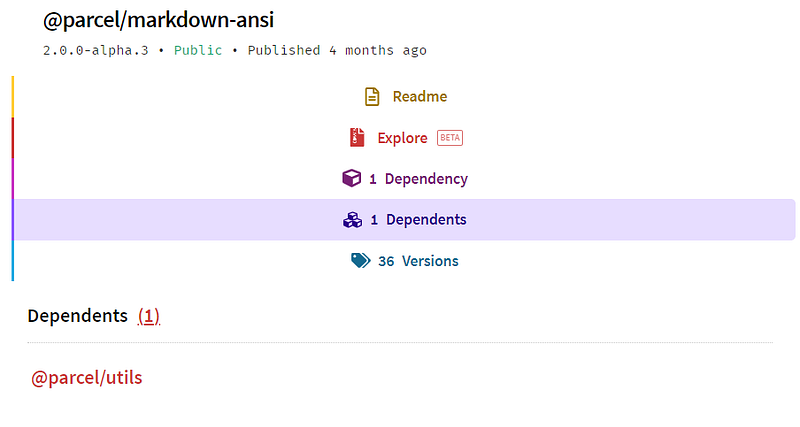 This Parcel package only has one package using it — itself.
This Parcel package only has one package using it — itself.Package overhead
When you look inside a node_modules directory, there’s likely hundreds if not thousands of packages, even for a relatively basic application. Quite often, a lot of these packages only contain a few lines of code, with an accompanying LICENSE, README and package.json file. It’s an incredibly amount of overhead and waste. Packages increasingly consume more hard drive space, increase installation times, and become more obscure in functionality to the point where some names literally describe what they do.
 Very common dependency in Node projects. We need fewer of these type of packages.
Very common dependency in Node projects. We need fewer of these type of packages.Monorepos are amplifying the problem. Quite often they unnecessarily split functionality into a separate package. If the only realistic consumer of a package is the monorepo, and you can’t realistically see normal users installing that 1 package out of 138 other packages in that repository, there’s probably no need to have it as a separate package. Ideally it would be better to let a user install 1 package that contains everything, and reduce the overhead.
Tracing Git history
The historical commits in a Git repository can be very important, especially if you need to discover how a package was changed over time and if you need to revert some changes that have been made. Some people would argue that a benefit of monorepos is that you can restore all packages at the same time so that they have the same compatibility. This is a good point, but it simplifies only one aspect of version control, while sacrificing on the other aspects. Most of the time for me, I want to revert a single package, or check the changes that have been made to that one package. In the context of a monorepo, this can become significantly more challenging. You would have to start applying filters to the search, but considering how tightly coupled packages in a monorepo tend to be, you still need to see what changes were made to those other related packages in a sea of hundreds of unrelated packages.
It’s worth noting that Git is simply not designed to work at the scale of a monorepo. The more files and commits in your repository, the slower it will become to do any basic command with Git. Atlassian provides some technical specifics on this topic.
Confusion for developers
Many monorepos publish their packages onto npm, and this can cause a few issues. The first issue is that if the developer is expected to install some of these packages, there can be confusion in regards to version numbers. If the packages are tightly coupled, it can be frustrating to figure out which package works with what. Some monorepos resolve this issue by keeping the version numbers in sync, but if you’re doing this, it again raises the question of why it’s worthwhile creating separate packages.
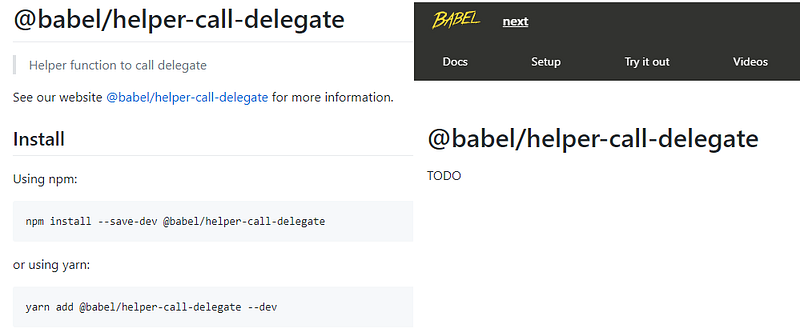 A publicly available Babel package with no documentation.
A publicly available Babel package with no documentation.Another issue is that publishing separate packages exposes private functionality. As much as you wish your users wouldn’t use undocumented functionality, if there’s a way to access it, a user will use it. This forces you as a developer to maintain backwards compatibility on that specific implementation detail. If you want to heavily modify the package, you likely will have to increment your major version number just because some people may be relying on that package existing with the undocumented API.
We have ESM modules now
One of the reasons for monorepos to exist previously and have several micro-packages was to improve bundling, ensuring that functionality you weren’t using wouldn’t be bundled with your app. Libraries such as Lodash famously popularized this pattern. If you only wanted to use a tiny piece of Lodash, you could import that package individually in order to exclude the rest of Lodash code. However with tree-shaking being common place in bundlers now, they’re beginning to be deprecated. With ESM support being everywhere now including NodeJS, there’s really no reason anymore to use separate packages as a means to reduce bundle sizes.
Private nested packages
Having said that though, there’s still a reason why you might want to consider having a separate package inside your repository. It can help simplify importing and bundling for the developer, without the need to publish those packages anywhere. Preact Compat is a great example of this. If you have optional files that a user can import, but you don’t want a user to have to reference a specific JavaScript file and you want the bundler to automatically pick the correct format for the environment, then having a separate package.json could help here.
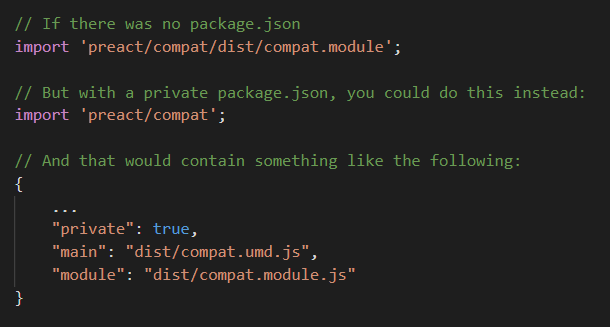
In the above example, the bundler can use a simplified path instead of pointing directly to a file, and can also determine whether or not to use the UMD or ESM version of the file based on the package metadata.
Conclusion
Like how monorepos over-engineer and separate too many features into packages, the opposite can be true for splitting code into too many repositories. There’s no silver bullet as to when one pattern makes sense over the other. You need to do a cost benefit analysis and ask yourself what are the benefits of having the feature as a separate package in one repository, as opposed to having it as a separate file that can be imported, or in a separate repository entirely. There’s always the maintenance overhead to be considered. For me personally, for all of the reasons I’ve listed above, I’m not convinced that monorepos are the way forward, and my advice is that they should be avoided.
Thanks for reading!